



AMD 正式发布基于全新「 GCN 」微架构设计、核心代号「 Tahiti 」的「 Radeon HD 7970 」高阶绘图卡,整合「 Vector Unit 」与「 Scalar Co-Processor 」单元令性能进一步提升,记忆体介面提升至 384Bit 宽度并搭载高达 3GB GDDR5 记忆体,率先新一代 PCI-Express 3.0 传输并提升至支援 DirectX 11.1 绘图规格。
一切由 VLIW 5 架构开始
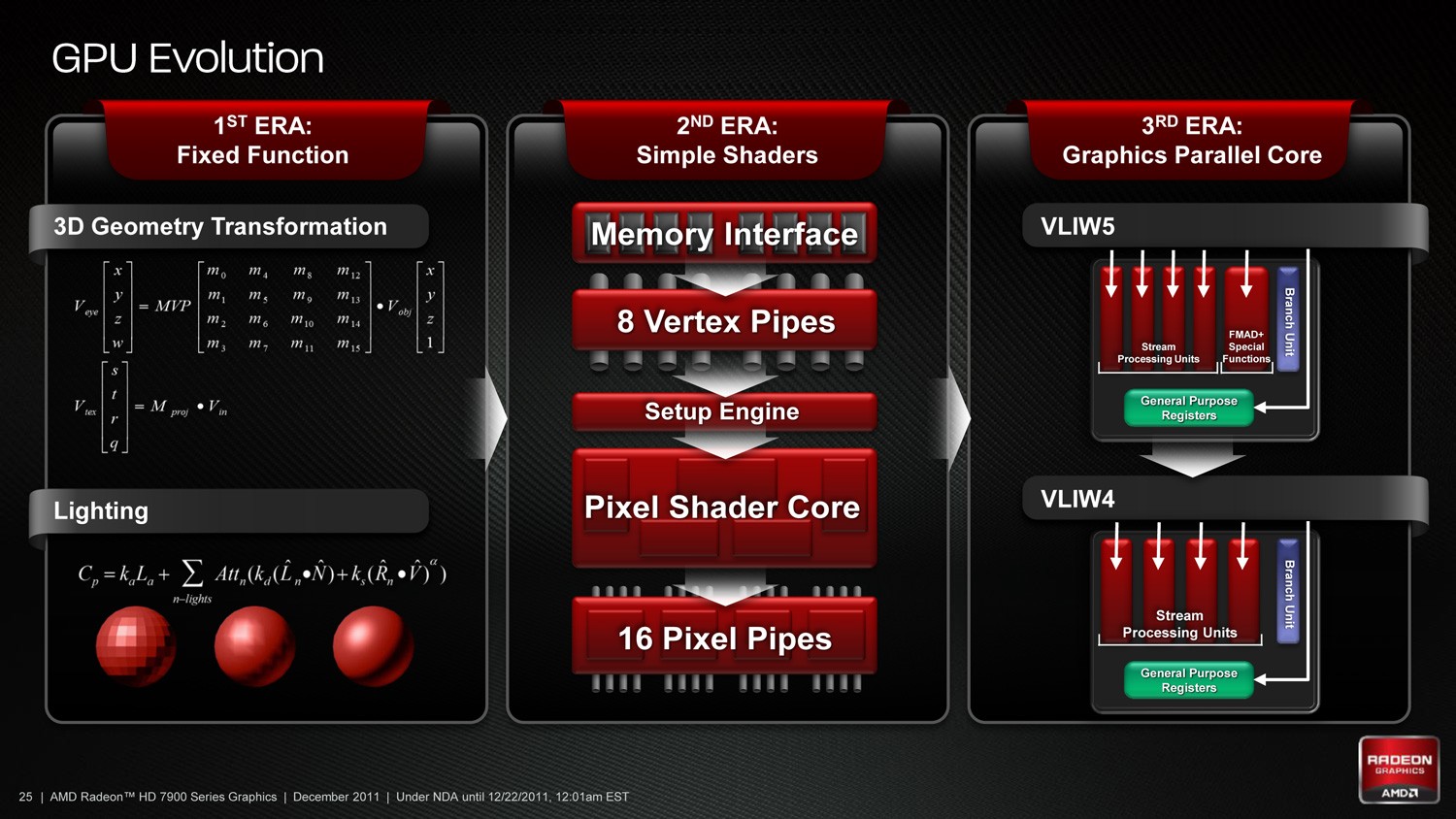
GPU 发展由 Fixed Fuction 、 Simple Shaders 发展至今日 Graphics Parallel Core
GPU 设计在进入 Direct X10 时代出现重大变化,由以往採用 Fixed Fuction 、 Simple Shaders 进化至 Graphics Parallel Core 设计,同时 GPU 亦不再局限于 3D 游戏及绘图应用,并朝向 GPGPU 通用运算发展, GPU 的用途变得更广泛,这一年 ATI ( 及后被 AMD 併购 ) 与 NVIDIA 均朝向 Unified Shader 方向发展,但微架构理念却各不相同。
ATI 决定选择 VLIW 架构 (Very Long Instruction Word) 的 SIMD 架构,每组 Stream Processor Unit 内建 5 个 ALU 运算单元,称为「 VLIW5 」微架构,这 5 个 ALU 单元并非全功能,其中 4 个 ALU 单一週期可运算 4 个 32Bit FP MAD 、 2 个 64Bit FP MUL / ADD 、 1 个 64Bit FP MAD 或是 4 个 24Bit Int MUL / ADD 指令,却不能执行 Special Function 或 Transcendentals 指令,余下的一个是专门化 ALU ,单一週期可处理一组 Special Function 或 Transcendentals 指令,或是 1 组 32Bit FP MAD 指令。

ATI R600 是首颗採用 VLIW 架构的 GPU 产品
採用「 VLIW5 」架构好处是 5 组 ALU 运算单元能共享一组 Branch Execution Unit 、 Registers 等单元,节省电晶体使用数,减低成本、晶片功耗及提升未来扩展性。同时, ATI 希望新架构在支援 DirectX 10 规格之余,亦能提共优势的 DirectX 9 的游戏性能,「 VLIW5 」架构正好能满足 DirectX 9 需要计算像素位置参数 (XYZW) 及颜色参数 (RGB) ,需要同时处理 4 笔资料的要求。
NVIDIA 选择了与 ATI 完全相异的 1D Scalar 的 MIMD 多指令多数据设计,每个 Stream Processor 仅内建 1 组全功能的 ALU ,并拥有独立的 Branch Execution Unit 、 Registers 等,虽然 Stream Processor 所需电晶体相较对手多, ALU 数目亦较对手为低,在最高运算理论值上不及对手,简单直接的 GPU 架构令内部单元运用效率高,不仅在 3D 性能上长期压倒对手,同时亦有利于 GPGPU 领域发展。

为平衡 DirectX 9 与 DirectX 10 性能, VLIW5 採用 4+1 ALU 设计
反观 ATI 的「 VLIW5 」需要把指令转译至 VLIW 指令并尽量填满 Stream Processor 的 ALU ,只可惜「 VLIW5 」架构内的 ALU 的功能并不完整,部份更具有特殊性执行条件, Ultra Threaded Dispatch Unit 需要把尽量把 5 个互相间并无依赖性的 Shader 指令,结合成一 5D VLIW 指令的难度甚高,虽然最理想情况下每个 Stream Processor 最高可完成 5 笔指令,但亦常出现只有 4 组 ALU 出现闲置的情况,导致运算能力只有理论值的 1/5 ,而平均指令填充率则在 2-3 个 ALU 单元之间,很视乎绘图程序设计及驱动程式优化,故此 AMD 绘图核心的最高运算效率理论值,往往与实际运算效率相距甚远。
为此 AMD 必需要努力优化驱动编译器,以避免运算单位闲置,同时不断增加 Stream Processors 数目,从 Radeon HD 2900XT 的 320 个猛增至 Radeon HD 5870 时的 1,600 个,实行以数量填补效率偏低问题。
进入 DirectX 11 时代, AMD 明白不断提升 Stream Processor 数目并非良策,不仅成本与功耗无法与对手比较,同时需要投放大量资源于优化驱动编译器上,因此 AMD 决定于 Radeon HD 6900 系列中採用经改良的「 VLIW4 」架构。
经改良的 VLIW4 架构
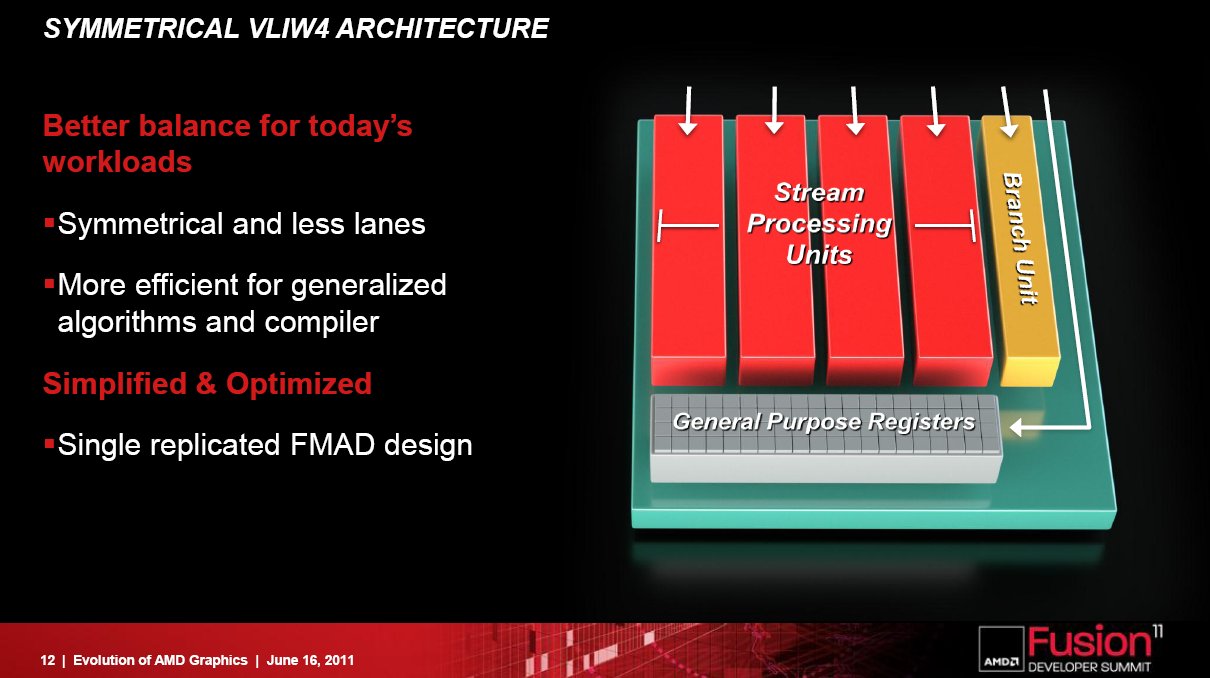
针对 VILW5 不足改良而成的 VILW4 , 4 个 ALU 功能完全相同有效减少运算单元闲置
AMD 在 Radeon HD 6900 系列中首次针对 VLIW 架构作出改良,虽然微架构仍沿自「 R600 」绘图核心,但 Stream Processor 则由「 VLIW5 」变成「 VLIW4 」设计。顾名思义「 VLIW4 」的 Streasm Processor 内建了 4 个 ALU 单元,数目比「 VLIW5 」少了一个 ALU ,删去了原本只针对 Special Function 或 Transcendentals 指令,或是 1 组 32Bit FP MAD 指令的 T-Unit 特殊运算单元,虽然每组 Stream Processor 拥有 ALU 运算单元数目减至 4 个,但这 4 个 ALU 却是功能性相同并具完整的。
「 VLIW4 」架构的 Stream Processor 单一週期处理 4 笔 32-Bit FMA 、 MAD 、 MUL 或 ADD 、或是 2 笔 64Bit ADD 、或是 1 笔 64Bit FMA 或 MUL 浮点运算指令。整数运算方面则支援单一週期处理 4 笔 24-Bit MAD 、 MUL 或 ADD 、或是 4 笔 32Bit ADD 或 bitwise 指令、或是 1 笔 32Bit MAD 或 MUL 整数运算、或是一笔 64Bit ADD 整数运算。
「 VLIW4 」把 4 个 ALU 功能变成全功能及对等,达成了 4-Way co-issue 支援,删去了 T-Unit 特殊运算单元,取而代之是 4 个 ALU 均能处理 Special Function 或 Transcendentals 指令,不过处理一组 Special Function 或 Transcendentals 指令的 ALU ,需要佔用 4-Way co-issue 中的其中 3 组 issue slot ,令 Stream Processor 内只余下 1 组可执行其他指令。

首颗採用「 VLIW4 」架构是採用代号「 Cayman 」绘图核心 Radeon HD 6950/6970
「 VLIW4 」由 5 个 ALU 减至 4 个 ALU ,令 VLIW 指令在排程及暂存器管理方面变得简单,预测分支与 VLIW 指令编绎较易处理,大大减少核心被闲置的机会,并可在相约的 SPU 数目下达成更高的绘图运算效能。
据 AMD 指出,全新「 VLIW4 」 Core 设计相较旧有的「 VLIW5 」 Core ,更有效把更多的指令填充至每个运算单元,简化了排程及暂存器管理工序, AMD 透过微架构改良,每 mm2晶片尺寸达成 10% 效能提升。
儘管「 VLIW4 」拥有不俗的性能提升,但「 VLIW4 」设计仍然有更大的改善空间,否则将无法与对手抗衡,在游戏性能方面需考虑如何减低 VLIW 编译器及驱动程式因素,令大部份游戏开发者无论驱动程式优化,即可提供强大的 3D 游戏性能。
同时﹐针对 GPGU 方面需进一步加强 Double Precision 指令的执行,现有的 Stream Processor 可以在单一週期内,每 1 个 ALU 处理完成 1 个 Singe Precision 指令,因此「 VLIW4 」单一週期 4 个 Single Precision 指令,但每个 Stream Processor 单一週期均只能执行 1 个 Double Precision 指令,在 GPGPU 应用上大幅落后对手。